1. 메모리 계층 구조
캐시에 대해서 이야기 하기 전 데이터를 저장하는 공간의 속도와 용량의 관계에 대해서 먼저 이야기 해보자.
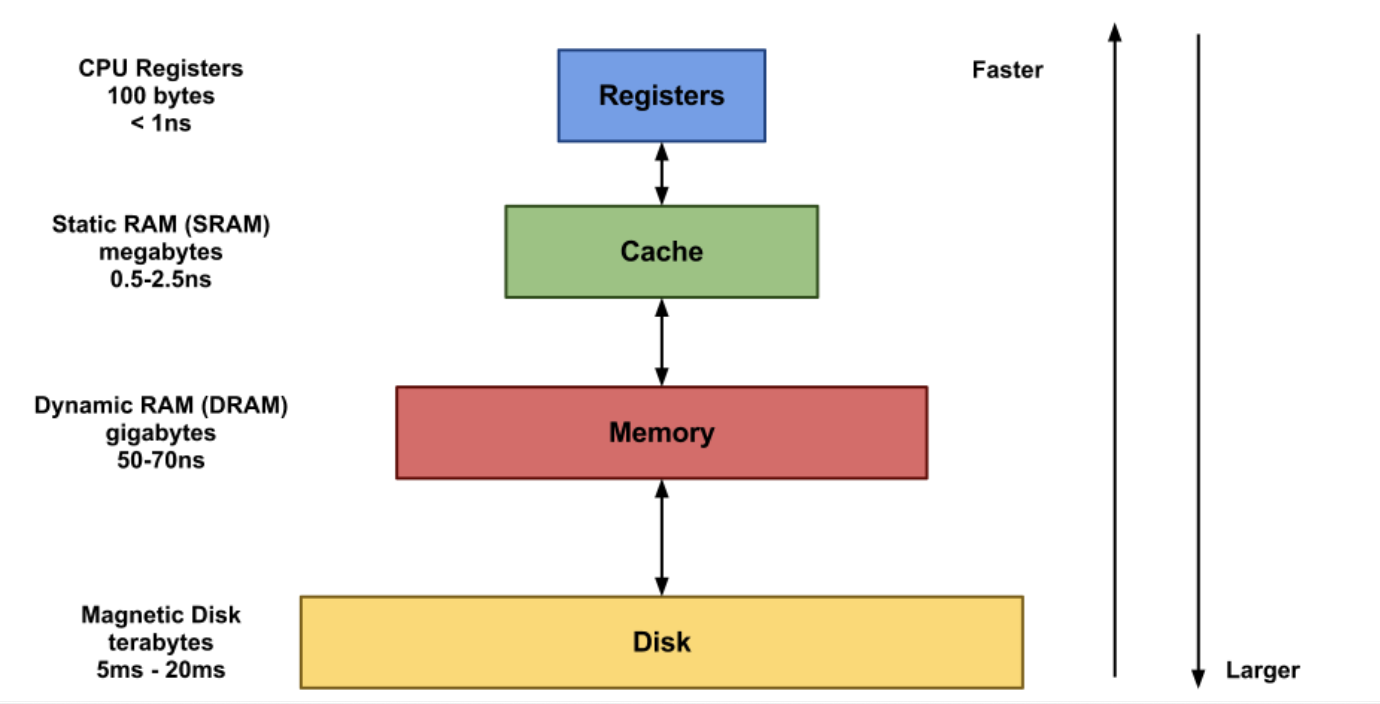
위의 그림으로 보면 아래쪽으로 갈수록 데이터를 저장할 수 있는 용량의 크기가 커지고 속도는 느려진다.
반대로 위쪽으로 갈수록 데이터를 저장하는 용량은 작아지지만 속도가 빨라진다.
이처럼 기본적이로 데이터를 저장하는 공간에서 속도와 저장용량은 반비례라고 생각할 수 있다.
사실 아래에서도 많은 이야기를 하겠지만 기본적으로 컴퓨터 공학의 발전은 효율을 굉장히 따지면서 큰 발전을 이루었던 것 같다. 속도도 빠르고 저장 용량도 크면 매우 좋겠지만 비용이 많이 들고 그러한 비용을 다른 곳에 쓰는 것이 더 큰 효율을 낼 수 있었다.
2. 파레토의 법칙
갑자기 파레토의 법칙을 이야기 하는 것이 이상하겠지만 아래의 내용들과 큰 연관이 있으니 설명해보겠다.
이탈리아의 경제학자 빌프레도 파레토가 발견한 파레토 현상은 원인과 결과가 있을 때 원인의 상위 20%가 전체 결과의 80%를 만든다는 법칙이다. 간단하게 설명하면 아래의 그림과 같다.

이러한 현상은 다양한 결과에서 나타날 수 있는데 컴퓨터 공학에서도 이 현상이 똑같이 나타나는 경우가 많다.
그렇다면 파레토의 법칙을 어떻게 활용하여 컴퓨터 공학적으로 효율을 더 극대화 할 수 있었을까?
3. 데이터 지역성의 원리
데이터 지역성의 원리 같은 경우 파레토의 법칙과 비슷하게 자주 쓰이는 데이터는 시간적 혹은 공간적으로 비슷한 공간에 몰려있을 가능성이 크다는 원리이다.
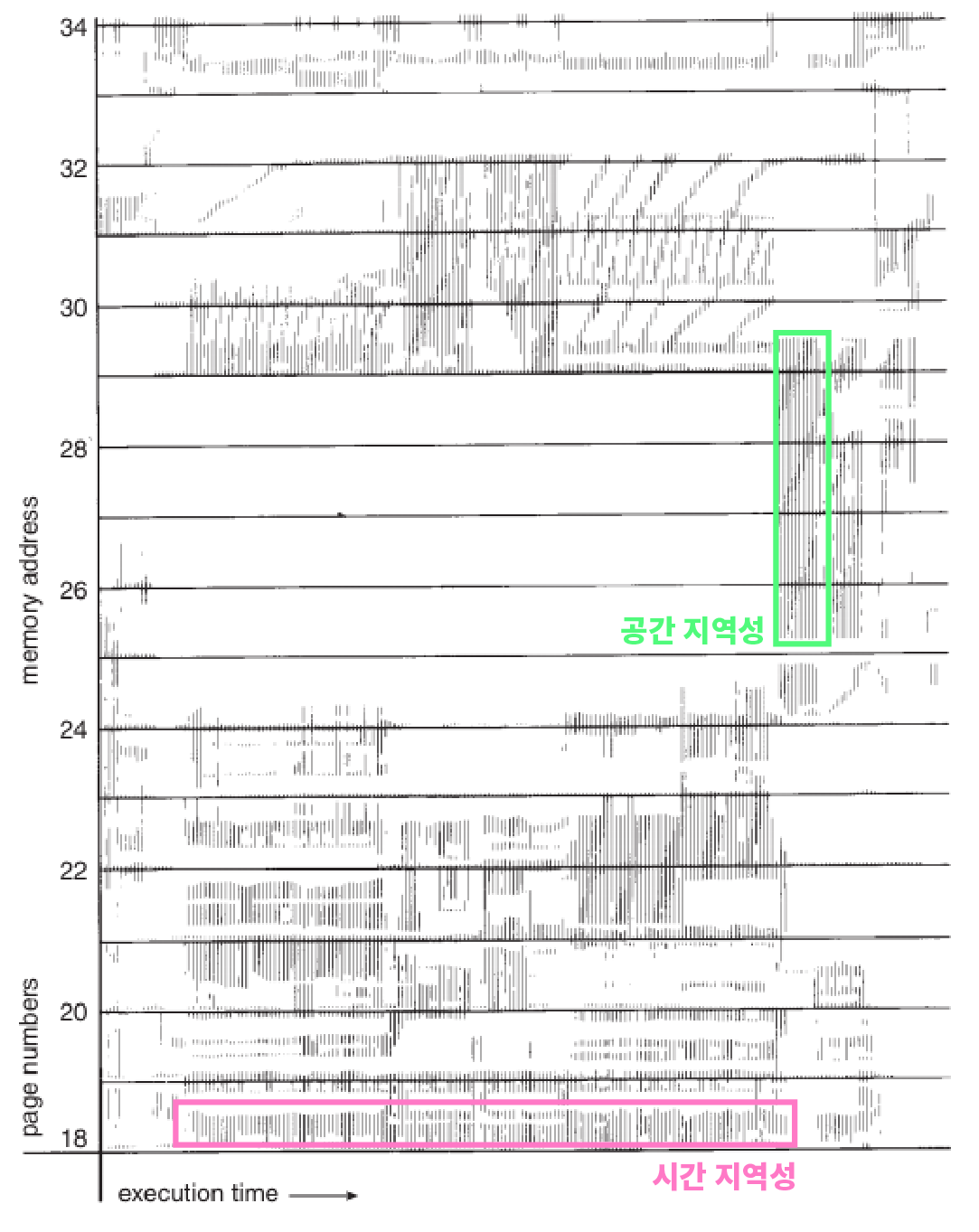
데이터 지역성에는 시간 지역성, 공간 지역성 이렇게 2가지가 대표적이다.
하지만 데이터 지역성의 경우 이번 포스팅에서 자세히 설명할 내용은 아니니 간단한 예로 대체하겠다.
- 시간 지역성의 경우 for문에서 조건 변수 int i=0을 선언 했을 때, 변수 i의 경우 for문이 끝나기 전까지 자주 쓰일 것이라는 것을 알 수 있다.
- 공간 지역성의 경우 for문에서 어떤 배열에 접근했다면 해당 배열이 위치한 메모리 공간은 for문이 끝나기 전까지 자주 쓰일 것이라는 것을 알 수 있다.
4. Cache란?
그렇다면 cache란 무엇이고 어떤 상황에 쓰이길래 메모리 계층 구조, 파레토의 법칙, 데이터 지역성읜 원리까지 길게 설명을 했을까?
cache란 간단하게 임시적으로 나중에 재사용될 것 같은 데이터를 나중에 효율적으로 빠르게 사용하기 위해 저장하는 것을 의미한다.
자주 사용되는 원본 데이터를 매번 사용할 때 마다 데이터베이스에서 찾아 사용하는 것은 비용이 많이 드는 행위이기 때문에 자주 사용되는 원본 데이터를 따로 캐시라는 임시 저장소에 저장한 뒤 빠르게 재사용한다.
캐시를 사용하는 예시로 웹브라우저와 웹 서버의 통신에 대한 예를 아래 그림으로 설명하겠다.

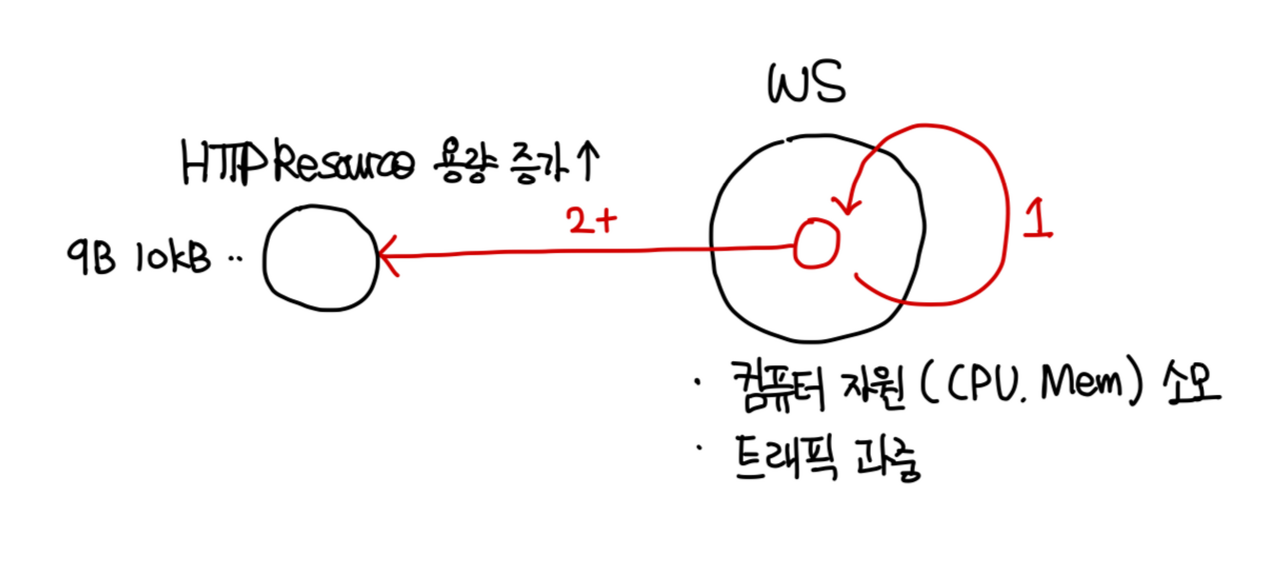
간략하게 이야기하자면 자주 사용되는 데이터를 저장하여 속도를 높이고 비용을 줄이는 방법으로 데이터를 찾는 방법이다. 이러한 매우 효율적인 방법으로 데이터를 찾고 사용할 수 있는 캐시는 다양한 곳에서 사용되어 다양한 캐시가 있다.
5. Cache 종류
캐시의 종류는 매우 다양한 것이 있지만 CPU캐시, HTTP 캐시, 서버 캐시 3가지 캐시에 대해서 알아보려고 한다.
1. CPU 캐시 : CPU 연산을 위해 메모리에서 값을 가져와서 사용후 폐기하는 것으로 간단하게 생각해 1+1을 연산한다고 했을 때 메모리에서 1, +, 1 을 가져온 뒤 메모리에 저장하여 2라는 값이 나올 때 까지 저장 후 2라는 값이 나오면 폐기한다고 생각하면 된다.
2. HTTP 캐시 : 웹 요청에 따른 결과(HTTP Resource 등)을 임시 저장 후 반복 요청 시 저장되었던 데이터를 반환한다.
3. 서버 캐시 : 로컬 캐시(LRU-Cache)와 글로벌 캐시(Redis 등)로 나뉘어져 자주 사용되는 데이터를 서버 캐시에 저장하는 것을 의미한다.
웹 브라우저와 웹 서버 사이에서 캐시가 동작하는 방식을 간단하게 표시하면 아래와 같다.

6. HTTP Cache의 종류
HTTP Cache의 경우 임시 저장 데이터(HTTP Resource)를 누가 필요로 하는가에 따라서 두가지로 나뉜다.
- A. Private : 임시 중간 저장소가 웹 브라우저 안에 있어 해당 웹 브라우저 유저 한명만을 위한 것
- B. Shared : 임시 중간 저장소가 웹 브라우저와 웹 서버 사이에 있어, 많은 웹 브라우저를 사용하는 유저 다수를 위한 것
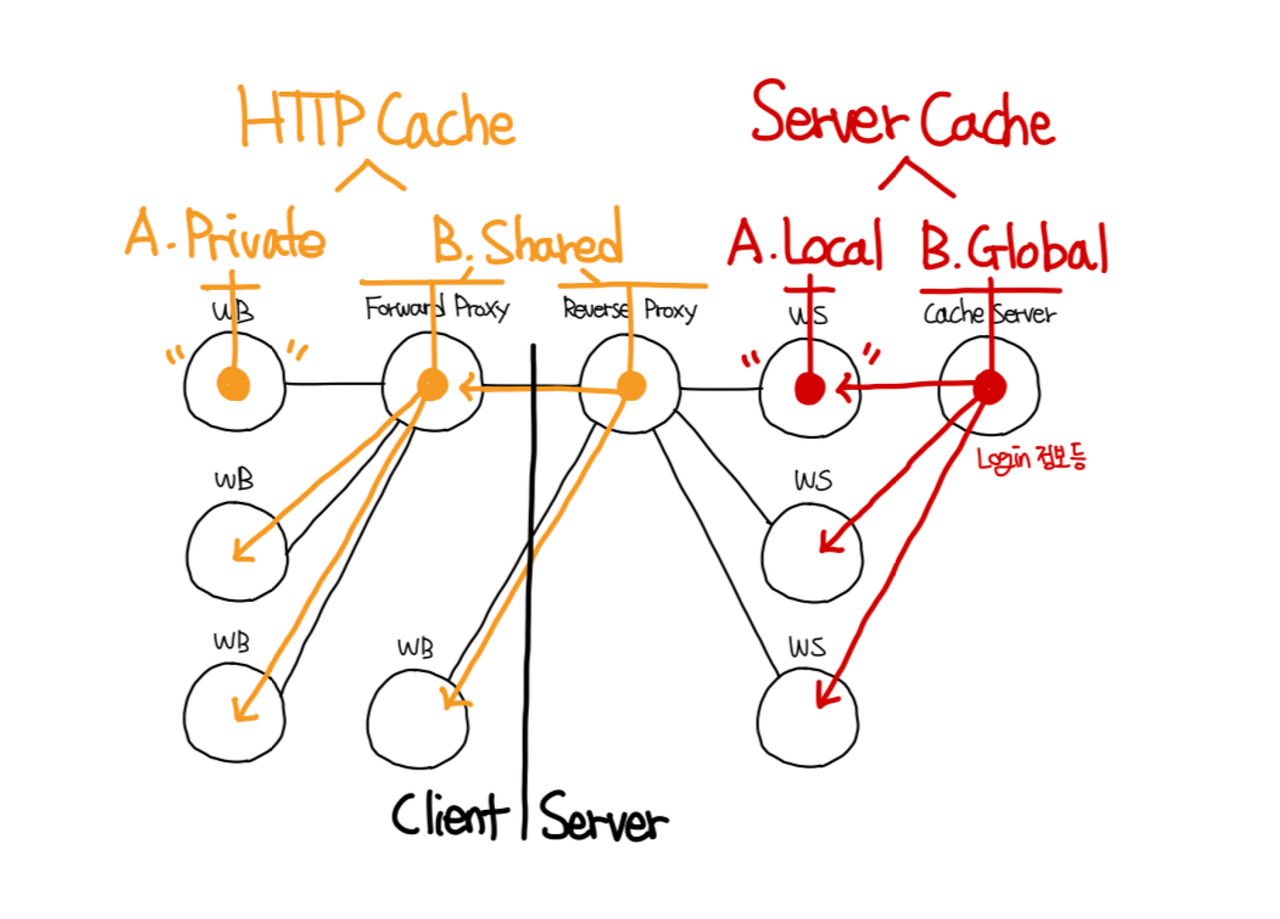
이때 B. Shared Cache의 경우 또 어떤 형태로 제어하는지에 따라서 두가지로 나뉜다.
- 프록시 캐시(그림에서 Forward Proxy) : 웹 서버 HTTP Cache 헤더 (Cache-Cotrol)를 통한 제어
- 관리형 캐시(그림에서 Reverse Proxy 혹은 CDN) : 서비스 개발자가 직접 정책 제어, 배포, 캐싱 할 데이터 직접 업로드 등
HTTP Cache를 정리하면 다음과 같다고 생각하면 된다.
- 임시 저장 데이터(HTTP Resource)를 필요로 하는 주체에 따라 A.Private, B.Shared로 나뉜다.
- B.Shared는 어떤 형태로 캐시가 제어되는지에 따라 Forward Proxy, Reverse Proxy(혹은 CDN)로 나뉜다.
- Private , Forward Proxy는 웹 서버가 반환하는 HTTP Cache 헤더(Cache-Control)를 통해 제어되어 수동적이다.
- Reverse Proxy(혹은 CDN)은 서비스 개발자가 직접 어떤 데이터들을 캐싱할지 업로드하고, 삭제하여 배포 및 제어한다.
- 추가적으로 Proxy의 경우 캐싱 뿐 아니라 추가적으로 다양한 요청에 대한 세부적인 추가작업을 진행할 수 있다.
7. HTTP Cache 이점
- 웹 서버 입장에서는 웹 서버의 부하를 완화 시킨다는 이점이 있다.
- 반복 연산 감소 : 웹 서버가 동적 웹 페이지를 생성하는 연산을 반복하지 않아도 된다.(캐시가 반환하기 때문에)
- 트래픽 분산 : 웹 서버가 모든 요청 트래픽을 받아내지 않아도 된다.(캐시가 일부 트래픽을 분담할 수 있기 때문에)
- 웹 브라우저 입장
- 네트워크 트래픽 감소(레이턴시 및 네트워크 대역폭 사용 감소)
- 유저 경험 증진
이외에도 HTTP Cache 제어 방법과 제어 정책, 재검증 주기, 조건부 요청 등 다루어야 할 내용이 많지만 이번 포스팅이 너무 길어 질 것 같아서 따로 포스팅을 해야 할 것 같다...
'Web 개요' 카테고리의 다른 글
| [Web] HTTP Stateless 해결을 위한 웹 저장소 및 웹 보안 (0) | 2024.01.11 |
|---|---|
| [Web] Forward Proxy / Reverse Proxy (0) | 2024.01.10 |
| [WEB] HTTP / HTTPS (1) | 2024.01.08 |
| [Web] 웹 브라우저 성능 개선 및 웹 서버 부하 완화 (2) | 2024.01.07 |
| [Web] 웹 구성 간 흐름 (1) | 2024.01.05 |



